

Perhaps the most valuable but difficult-to-learn skill any technical person could have is the ability to troubleshoot a system. For those unfamiliar with the term, troubleshooting means the act of pinpointing and correcting problems in any kind of system. For an auto mechanic, this means determining and fixing problems in cars based on the car's behavior. For a doctor, this means correctly diagnosing a patient's malady and prescribing a cure. For a business expert, this means identifying the source(s) of inefficiency in a corporation and recommending corrective measures.
Troubleshooters must be able to determine the cause or causes of a problem simply by examining its effects. Rarely does the source of a problem directly present itself for all to see. Cause/effect relationships are often complex, even for seemingly simple systems, and often the proficient troubleshooter is regarded by others as something of a miracle-worker for their ability to quickly discern the root cause of a problem. While some people are gifted with a natural talent for troubleshooting, it is a skill that can be learned like any other.
Sometimes the system to be analyzed is in so bad a state of affairs that there is no hope of ever getting it working again. When investigators sift through the wreckage of a crashed airplane, or when a doctor performs an autopsy, they must do their best to determine the cause of massive failure after the fact. Fortunately, the task of the troubleshooter is usually not this grim. Typically, a misbehaving system is still functioning to some degree and may be stimulated and adjusted by the troubleshooter as part of the diagnostic procedure. In this sense, troubleshooting is a lot like scientific method: determining cause/effect relationships by means of live experimentation.
Like science, troubleshooting is a mixture of standard procedure and personal creativity. There are certain procedures employed as tools to discern cause(s) from effects, but they are impotent if not coupled with a creative and inquisitive mind. In the course of troubleshooting, the troubleshooter may have to invent their own specific technique -- adapted to the particular system they're working on -- and/or modify tools to perform a special task. Creativity is necessary in examining a problem from different perspectives: learning to ask different questions when the "standard" questions don't lead to fruitful answers.
If there is one personality trait I've seen positively associated with excellent troubleshooting more than any other, it's technical curiosity. People fascinated by learning how things work, and who aren't discouraged by a challenging problem, tend to be better at troubleshooting than others. Richard Feynman, the late physicist who taught at Caltech for many years, illustrates to me the ultimate troubleshooting personality. Reading any of his (auto)biographical books is both educating and entertaining, and I recommend them to anyone seeking to develop their own scientific reasoning/troubleshooting skills.
These preliminary questions are not trivial. Indeed, they are essential to expedient and safe troubleshooting. They are especially important when the system to be troubleshot is large, dangerous, and/or expensive.
Sometimes the troubleshooter will be required to work on a system that is still in full operation (perhaps the ultimate example of this is a doctor diagnosing a live patient). Once the cause or causes are determined to a high degree of certainty, there is the step of corrective action. Correcting a system fault without significantly interrupting the operation of the system can be very challenging, and it deserves thorough planning.
When there is high risk involved in taking corrective action, such as is the case with performing surgery on a patient or making repairs to an operating process in a chemical plant, it is essential for the worker(s) to plan ahead for possible trouble. One question to ask before proceeding with repairs is, "how and at what point(s) can I abort the repairs if something goes wrong?" In risky situations, it is vital to have planned "escape routes" in your corrective action, just in case things do not go as planned. A surgeon operating on a patient knows if there are any "points of no return" in such a procedure, and stops to re-check the patient before proceeding past those points. He or she also knows how to "back out" of a surgical procedure at those points if needed.
When first approaching a failed or otherwise misbehaving system, the new troubleshooter often doesn't know where to begin. The following strategies are not exhaustive by any means, but provide the troubleshooter with a simple checklist of questions to ask in order to start isolating the problem.
As tips, these troubleshooting suggestions are not comprehensive procedures: they serve as starting points only for the troubleshooting process. An essential part of expedient troubleshooting is probability assessment, and these tips help the troubleshooter determine which possible points of failure are more or less likely than others. Final isolation of the system failure is usually determined through more specific techniques (outlined in the next section -- Specific Troubleshooting Techniques).
If this device or process has been historically known to fail in a certain particular way, and the conditions leading to this common failure have not changed, check for this "way" first.
Example: The car's engine is overheating. The last two times this happened, the cause was low coolant level in the radiator.
What to do: Check the coolant level first. Of course, past history by no means guarantees the present symptoms are caused by the same problem, but since this is more likely, it makes sense to check this first.
If, however, the cause of routine failure in a system has been corrected (i.e. the leak causing low coolant level in the past has been repaired), then this may not be a probable cause of trouble this time.
If a system has been having problems immediately after some kind of maintenance or other change, the problems might be linked to those changes.
Example: The mechanic recently tuned my car's engine, and now I hear a rattling noise that I didn't hear before I took the car in for repair.
What to do: Check for something that may have been left loose by the mechanic after his or her tune-up work.
If a system isn't producing the desired end result, look for what it is doing correctly; in other words, identify where the problem is not, and focus your efforts elsewhere. Whatever components or subsystems necessary for the properly working parts to function are probably okay. The degree of fault can often tell you what part of it is to blame.
Example: The radio works fine on the AM band, but not on the FM band.
What to do: Eliminate from the list of possible causes, anything in the radio necessary for the AM band's function. Whatever the source of the problem is, it is specific to the FM band and not to the AM band. This eliminates the audio amplifier, speakers, fuse, power supply, and almost all external wiring. Being able to eliminate sections of the system as possible failures reduces the scope of the problem and makes the rest of the troubleshooting procedure more efficient.
Based on your knowledge of how a system works, think of various kinds of failures that would cause this problem (or these phenomena) to occur, and check for those failures (starting with the most likely based on circumstances, history, or knowledge of component weaknesses).
Example: The car's engine is overheating.
What to do: Consider possible causes for overheating, based on what you know of engine operation. Either the engine is generating too much heat, or not getting rid of the heat well enough (most likely the latter). Brainstorm some possible causes: a loose fan belt, clogged radiator, bad water pump, low coolant level, etc. Investigate each one of those possibilities before investigating alternatives.
After applying some of the general troubleshooting tips to narrow the scope of a problem's location, there are techniques useful in further isolating it. Here are a few:
In a system with identical or parallel subsystems, swap components between those subsystems and see whether or not the problem moves with the swapped component. If it does, you've just swapped the faulty component; if it doesn't, keep searching!
This is a powerful troubleshooting method, because it gives you both a positive and a negative indication of the swapped component's fault: when the bad part is exchanged between identical systems, the formerly broken subsystem will start working again and the formerly good subsystem will fail.
I was once able to troubleshoot an elusive problem with an automotive engine ignition system using this method: I happened to have a friend with an automobile sharing the exact same model of ignition system. We swapped parts between the engines (distributor, spark plug wires, ignition coil -- one at a time) until the problem moved to the other vehicle. The problem happened to be a "weak" ignition coil, and it only manifested itself under heavy load (a condition that could not be simulated in my garage). Normally, this type of problem could only be pinpointed with an ignition system analyzer (or oscilloscope) and a dynamometer to simulate extreme driving conditions. This technique, however, confirmed the source of the problem with 100% accuracy, using no diagnostic equipment whatsoever.
Sometimes, you may swap a part and find that the problem has changed, but has not gone away. This tells you that the components you just swapped are somehow different (different calibration, different function), and nothing more. However, don't dismiss this information just because it doesn't lead you straight to the problem -- look for other changes in the system as a whole as a result of the swap, and try to figure out what these changes tell you about the source of the problem.
Example 1: You're working on a CNC machine tool with X, Y, and Z-axis drives. The Y axis is not working, but the X and Z axes are working. All three axes share identical components (feedback encoders, servo motor drives, servo motors).
What to do: Exchange these identical components, one at a time, Y axis and either one of the working axes (X or Z), and see after each swap whether or not the problem has moved with the swap.
Example 2: A stereo system produces no sound on the left speaker, but the right speaker works just fine.
What to do: Try swapping respective components between the two channels and see if the problem changes sides, from left to right. When it does, you've found the defective component. For instance, you could swap the speakers between channels: if the problem moves to the other side (i.e. the same speaker that was dead before is still dead, now that it's connected to the right channel cable) then you know that speaker is bad. If the problem stays on the same side (i.e. the speaker formerly silent is now producing sound after having been moved to the other side of the room and connected to the other cable), then you know the speakers are fine, and the problem must lie somewhere else (perhaps in the cable connecting the silent speaker to the amplifier, or in the amplifier itself).
If the speakers have been verified as good, then you could check the cables using the same method. Swap the cables so that each one now connects to the other channel of the amplifier and to the other speaker. Again, if the problem changes sides (i.e. now the right speaker is now "dead" and the left speaker now produces sound), then the cable now connected to the right speaker must be defective. If neither swap (the speakers nor the cables) causes the problem to change sides from left to right, then the problem must lie within the amplifier (i.e. the left channel output must be "dead").
If a system is composed of several parallel or redundant components which can be removed without crippling the whole system, start removing these components (one at a time) and see if things start to work again.
Example 1: A "star" topology communications network between several computers has failed. None of the computers are able to communicate with each other.
What to do: Try unplugging the computers, one at a time from the network, and see if the network starts working again after one of them is unplugged. If it does, then that last unplugged computer may be the one at fault (it may have been "jamming" the network by constantly outputting data or noise).
Example 2: A household fuse keeps blowing (or the breaker keeps tripping open) after a short amount of time.
What to do: Unplug appliances from that circuit until the fuse or breaker quits interrupting the circuit. If you can eliminate the problem by unplugging a single appliance, then that appliance might be defective. If you find that unplugging almost any appliance solves the problem, then the circuit may simply be overloaded by too many appliances, neither of them defective.
In a system with multiple sections or stages, carefully measure the variables going in and out of each stage until you find a stage where things don't look right.
Example 1: A radio is not working (producing no sound at the speaker))
What to do: Divide the circuitry into stages: tuning stage, mixing stages, amplifier stage, all the way through to the speaker(s). Measure signals at test points between these stages and tell whether or not a stage is working properly.
Example 2: An analog summer circuit is not functioning properly.
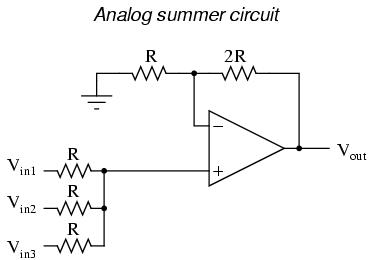
What to do: I would test the passive averager network (the three resistors at the lower-left corner of the schematic) to see that the proper (averaged) voltage was seen at the noninverting input of the op-amp. I would then measure the voltage at the inverting input to see if it was the same as at the noninverting input (or, alternatively, measure the voltage difference between the two inputs of the op-amp, as it should be zero). Continue testing sections of the circuit (or just test points within the circuit) to see if you measure the expected voltages and currents.
Closely related to the strategy of dividing a system into sections, this is actually a design and fabrication technique useful for new circuits, machines, or systems. It's always easier begin the design and construction process in little steps, leading to larger and larger steps, rather than to build the whole thing at once and try to troubleshoot it as a whole.
Suppose that someone were building a custom automobile. He or she would be foolish to bolt all the parts together without checking and testing components and subsystems as they went along, expecting everything to work perfectly after it's all assembled. Ideally, the builder would check the proper operation of components along the way through the construction process: start and tune the engine before it's connected to the drivetrain, check for wiring problems before all the cover panels are put in place, check the brake system in the driveway before taking it out on the road, etc.
Countless times I've witnessed students build a complex experimental circuit and have trouble getting it to work because they didn't stop to check things along the way: test all resistors before plugging them into place, make sure the power supply is regulating voltage adequately before trying to power anything with it, etc. It is human nature to rush to completion of a project, thinking that such checks are a waste of valuable time. However, more time will be wasted in troubleshooting a malfunctioning circuit than would be spent checking the operation of subsystems throughout the process of construction.
Take the example of the analog summer circuit in the previous section for example: what if it wasn't working properly? How would you simplify it and test it in stages? Well, you could reconnect the op-amp as a basic comparator and see if it's responsive to differential input voltages, and/or connect it as a voltage follower (buffer) and see if it outputs the same analog voltage as what is input. If it doesn't perform these simple functions, it will never perform its function in the summer circuit! By stripping away the complexity of the summer circuit, paring it down to an (almost) bare op-amp, you can test that component's functionality and then build from there (add resistor feedback and check for voltage amplification, then add input resistors and check for voltage summing), checking for expected results along the way.
Set up instrumentation (such as a datalogger, chart recorder, or multimeter set on "record" mode) to monitor a signal over a period of time. This is especially helpful when tracking down intermittent problems, which have a way of showing up the moment you've turned your back and walked away.
This may be essential for proving what happens first in a fast-acting system. Many fast systems (especially shutdown "trip" systems) have a "first out" monitoring capability to provide this kind of data.
Example #1: A turbine control system shuts automatically in response to an abnormal condition. By the time a technician arrives at the scene to survey the turbine's condition, however, everything is in a "down" state and it's impossible to tell what signal or condition was responsible for the initial shutdown, as all operating parameters are now "abnormal."
What to do: One technician I knew used a videocamera to record the turbine control panel, so he could see what happened (by indications on the gauges) first in an automatic-shutdown event. Simply by looking at the panel after the fact, there was no way to tell which signal shut the turbine down, but the videotape playback would show what happened in sequence, down to a frame-by-frame time resolution.
Example #2: An alarm system is falsely triggering, and you suspect it may be due to a specific wire connection going bad. Unfortunately, the problem never manifests itself while you're watching it!
What to do: Many modern digital multimeters are equipped with "record" settings, whereby they can monitor a voltage, current, or resistance over time and note whether that measurement deviates substantially from a regular value. This is an invaluable tool for use in "intermittent" electronic system failures.
The following problems are arranged in order from most likely to least likely, top to bottom. This order has been determined largely from personal experience troubleshooting electrical and electronic problems in automotive, industry, and home applications. This order also assumes a circuit or system that has been proven to function as designed and has failed after substantial operation time. Problems experienced in newly assembled circuits and systems do not necessarily exhibit the same probabilities of occurrence.
As incredible as this may sound to the new student of electronics, a high percentage of electrical and electronic system problems are caused by a very simple source of trouble: poor (i.e. open or shorted) wire connections. This is especially true when the environment is hostile, including such factors as high vibration and/or a corrosive atmosphere. Connection points found in any variety of plug-and-socket connector, terminal strip, or splice are at the greatest risk for failure. The category of "connections" also includes mechanical switch contacts, which can be thought of as a high-cycle connector. Improper wire termination lugs (such as a compression-style connector crimped on the end of a solid wire -- a definite faux pas) can cause high-resistance connections after a period of trouble-free service.
It should be noted that connections in low-voltage systems tend to be far more troublesome than connections in high-voltage systems. The main reason for this is the effect of arcing across a discontinuity (circuit break) in higher-voltage systems tends to blast away insulating layers of dirt and corrosion, and may even weld the two ends together if sustained long enough. Low-voltage systems tend not to generate such vigorous arcing across the gap of a circuit break, and also tend to be more sensitive to additional resistance in the circuit. Mechanical switch contacts used in low-voltage systems benefit from having the recommended minimum wetting current conducted through them to promote a healthy amount of arcing upon opening, even if this level of current is not necessary for the operation of other circuit components.
Although open failures tend to more common than shorted failures, "shorts" still constitute a substantial percentage of wiring failure modes. Many shorts are caused by degradation of wire insulation. This, again, is especially true when the environment is hostile, including such factors as high vibration, high heat, high humidity, or high voltage. It is rare to find a mechanical switch contact that is failed shorted, except in the case of high-current contacts where contact "welding" may occur in overcurrent conditions. Shorts may also be caused by conductive buildup across terminal strip sections or the backs of printed circuit boards.
A common case of shorted wiring is the ground fault, where a conductor accidently makes contact with either earth or chassis ground. This may change the voltage(s) present between other conductors in the circuit and ground, thereby causing bizarre system malfunctions and/or personnel hazard.
These generally consist of tripped overcurrent protection devices or damage due to overheating. Although power supply circuitry is usually less complex than the circuitry being powered, and therefore should figure to be less prone to failure on that basis alone, it generally handles more power than any other portion of the system and therefore must deal with greater voltages and/or currents. Also, because of its relative design simplicity, a system's power supply may not receive the engineering attention it deserves, most of the engineering focus devoted to more glamorous parts of the system.
Active components (amplification devices) tend to fail with greater regularity than passive (non-amplifying) devices, due to their greater complexity and tendency to amplify overvoltage/overcurrent conditions. Semiconductor devices are notoriously prone to failure due to electrical transient (voltage/current surge) overloading and thermal (heat) overloading. Electron tube devices are far more resistant to both of these failure modes, but are generally more prone to mechanical failures due to their fragile construction.
Nonamplifying components are the most rugged of all, their relative simplicity granting them a statistical advantage over active devices. The following list gives an approximate relation of failure probabilities (again, top being the most likely and bottom being the least likely):
"All men are liable to error;"
John Locke
Whereas the last section deals with component failures in systems that have been successfully operating for some time, this section concentrates on the problems plaguing brand-new systems. In this case, failure modes are generally not of the aging kind, but are related to mistakes in design and assembly caused by human beings.
In this case, bad connections are usually due to assembly error, such as connection to the wrong point or poor connector fabrication. Shorted failures are also seen, but usually involve misconnections (conductors inadvertently attached to grounding points) or wires pinched under box covers.
Another wiring-related problem seen in new systems is that of electrostatic or electromagnetic interference between different circuits by way of close wiring proximity. This kind of problem is easily created by routing sets of wires too close to each other (especially routing signal cables close to power conductors), and tends to be very difficult to identify and locate with test equipment.
Blown fuses and tripped circuit breakers are likely sources of trouble, especially if the project in question is an addition to an already-functioning system. Loads may be larger than expected, resulting in overloading and subsequent failure of power supplies.
In the case of a newly-assembled system, component fault probabilities are not as predictable as in the case of an operating system that fails with age. Any type of component -- active or passive -- may be found defective or of imprecise value "out of the box" with roughly equal probability, barring any specific sensitivities in shipping (i.e fragile vacuum tubes or electrostatically sensitive semiconductor components). Moreover, these types of failures are not always as easy to identify by sight or smell as an age- or transient-induced failure.
Increasingly seen in large systems using microprocessor-based components, "programming" issues can still plague non-microprocessor systems in the form of incorrect time-delay relay settings, limit switch calibrations, and drum switch sequences. Complex components having configuration "jumpers" or switches to control behavior may not be "programmed" properly.
Components may be used in a new system outside of their tolerable ranges. Resistors, for example, with too low of power ratings, of too great of tolerance, may have been installed. Sensors, instruments, and controlling mechanisms may be uncalibrated, or calibrated to the wrong ranges.
Perhaps the most difficult to pinpoint and the slowest to be recognized (especially by the chief designer) is the problem of design error, where the system fails to function simply because it cannot function as designed. This may be as trivial as the designer specifying the wrong components in a system, or as fundamental as a system not working due to the designer's improper knowledge of physics.
I once saw a turbine control system installed that used a low-pressure switch on the lubrication oil tubing to shut down the turbine if oil pressure dropped to an insufficient level. The oil pressure for lubrication was supplied by an oil pump turned by the turbine. When installed, the turbine refused to start. Why? Because when it was stopped, the oil pump was not turning, thus there was no oil pressure to lubricate the turbine. The low-oil-pressure switch detected this condition and the control system maintained the turbine in shutdown mode, preventing it from starting. This is a classic example of a design flaw, and it could only be corrected by a change in the system logic.
While most design flaws manifest themselves early in the operational life of the system, some remain hidden until just the right conditions exist to trigger the fault. These types of flaws are the most difficult to uncover, as the troubleshooter usually overlooks the possibility of design error due to the fact that the system is assumed to be "proven." The example of the turbine lubrication system was a design flaw impossible to ignore on start-up. An example of a "hidden" design flaw might be a faulty emergency coolant system for a machine, designed to remain inactive until certain abnormal conditions are reached -- conditions which might never be experienced in the life of the system.
Fallacious reasoning and false assumptions account for more failed or belabored troubleshooting efforts than any other impediments. With this in mind, the aspiring troubleshooter needs to be familiar with a few common troubleshooting mistakes.
Trusting that a brand-new component will always be good. While it is generally true that a new component will be in good condition, it is not always true. It is also possible that a component has been mis-labeled and may have the wrong value (usually this mis-labeling is a mistake made at the point of distribution or warehousing and not at the manufacturer, but again, not always!).
Not periodically checking your test equipment. This is especially true with battery-powered meters, as weak batteries may give spurious readings. When using meters to safety-check for dangerous voltage, remember to test the meter on a known source of voltage both before and after checking the circuit to be serviced, to make sure the meter is in proper operating condition.
Assuming there is only one failure to account for the problem. Single-failure system problems are ideal for troubleshooting, but sometimes failures come in multiple numbers. In some instances, the failure of one component may lead to a system condition that damages other components. Sometimes a component in marginal condition goes undetected for a long time, then when another component fails the system suffers from problems with both components.
Mistaking causality for coincidence. Just because two events occurred at nearly the same time does not necessarily mean one event caused the other! They may be both consequences of a common cause, or they may be totally unrelated! If possible, try to duplicate the same condition suspected to be the cause and see if the event suspected to be the coincidence happens again. If not, then there is either no causal relationship as assumed. This may mean there is no causal relationship between the two events whatsoever, or that there is a causal relationship, but just not the one you expected.
Self-induced blindness. After a long effort at troubleshooting a difficult problem, you may become tired and begin to overlook crucial clues to the problem. Take a break and let someone else look at it for a while, or let them help you. You'll be amazed at what a difference this can make!